2016245053 DeepLearning_Tensorflow
텐서
import tensorflow as tf
import numpy as np
텐서는 dtype-균일한 배열이라 불리는 다차원 배열입니다.
Numpy의 np.arrays와 비슷하지만 Python의 숫자 및 문자열과 같이 변경할 수 없어 업데이트가 불가능하고 새 텐서를 만들수만 있습니다.
기초 - 기본 텐서
0순위-스칼라 텐서
0순위 텐서는 단일 값을 가지며 축이 없습니다. 기본적으로 int32 텐서가 됩니다.
rank_0_tensor = tf.constant(4)
print(rank_0_tensor)
output
tf.Tensor(4, shape=(), dtype=int32)
1순위-벡터 텐서
벡터 텐서는 값들의 목록(list)과 같으며 하나의 축을 가지고 있습니다.
rank_1_tensor = tf.constant([1.0, 2.0, 3.0])
print(rank_1_tensor)
output
tf.Tensor([1. 2. 3.], shape=(3,), dtype=float32)
마침 값에 소숫점을 추가해주자 dtype이 float32로 바뀌었습니다.
여기서 파이선 텐서플로우에선 주어진 값에 따라 dtype이 바뀐다는 것을 알 수 있습니다.
참고로 ‘tf.Tensor’의 데이터 유형을 검사하려면, ‘Tensor.dtype’ 속성을 사용합니다.
2순위-행렬
행렬 텐서는 2개의 축을 가지고 있습니다.
값을 주면서 임의의 dtype을 설정해 줄 수 있습니다.
rank_2_tensor = tf.constant([[1, 2],
[3, 4],
[5, 6]], dtype=tf.float16)
print(rank_2_tensor)
output
tf.Tensor(
[[1. 2.]
[3. 4.]
[5. 6.]], shape=(3, 2), dtype=float16)
설정해준 dtype의 형태로 출력되었습니다.
3축 텐서
텐서는 2개 이상의 축을 가질 수 있습니다. 아래는 3개 축을 가진 텐서입니다.
rank_3_tensor = tf.constant([
[[0, 1, 2, 3, 4],
[5, 6, 7, 8, 9]],
[[10, 11, 12, 13, 14],
[15, 16, 17, 18, 19]],
[[20, 21, 22, 23, 24],
[25, 26, 27, 28, 29]],])
print(rank_3_tensor)
output
tf.Tensor(
[[[ 0 1 2 3 4]
[ 5 6 7 8 9]]
[[10 11 12 13 14]
[15 16 17 18 19]]
[[20 21 22 23 24]
[25 26 27 28 29]]], shape=(3, 2, 5), dtype=int32)
NumPy 배열 변환
np.array 또는 tensor.numpy 메소드를 사용하여 텐서를 NumPy 배열로 변환할 수 있습니다.
np.array(rank_2_tensor)
output
array([[1., 2.],
[3., 4.],
[5., 6.]], dtype=float16)
rank_2_tensor.numpy()
output
array([[1., 2.],
[3., 4.],
[5., 6.]], dtype=float16)
텐서에는 float와 int 말고도 complex numbers(복소수)와 strings(문자열)이 있습니다.
기본 tf.Tensor 클래스에선 텐서가 각 축에 따라 모든 요소의 크기가 같은 직사각형 이어야 합니다.
산술 연산
텐서에 대한 산술을 수행할 수 있습니다.
a = tf.constant([[1, 2],
[3, 4]])
b = tf.constant([[1, 1],
[1, 1]])
print(tf.add(a, b), "\n") #덧셈
print(tf.multiply(a, b), "\n") #값끼리 곱셈
print(tf.matmul(a, b), "\n") #행렬의 곱셈
print(tf.subtract(a, b), "\n") #뺄셈
print(tf.divide(a, b)) #나눗셈
output
tf.Tensor(
[[2 3]
[4 5]], shape=(2, 2), dtype=int32)
tf.Tensor(
[[1 2]
[3 4]], shape=(2, 2), dtype=int32)
tf.Tensor(
[[3 3]
[7 7]], shape=(2, 2), dtype=int32)
tf.Tensor(
[[0 1]
[2 3]], shape=(2, 2), dtype=int32)
tf.Tensor(
[[1. 2.]
[3. 4.]], shape=(2, 2), dtype=float64)
직접 연산도 가능합니다.
print(a + b, "\n") #덧셈
print(a * b, "\n") #값끼리 곱셈(multiply)
print(a @ b) #행렬의 곱셈(matmul)
output
tf.Tensor(
[[2 3]
[4 5]], shape=(2, 2), dtype=int32)
tf.Tensor(
[[1 2]
[3 4]], shape=(2, 2), dtype=int32)
tf.Tensor(
[[3 3]
[7 7]], shape=(2, 2), dtype=int32)
모든 종류의 연산(ops)에도 사용할 수 있습니다.
c = tf.constant([[4.0, 5.0], [10.0, 1.0]])
print(tf.reduce_max(c)) #가장 큰 값
print(tf.argmax(c)) #가장 큰 값의 인덱스
print(tf.nn.softmax(c)) #softmax 연산
output
tf.Tensor(10.0, shape=(), dtype=float32)
tf.Tensor([1 0], shape=(2,), dtype=int64)
tf.Tensor(
[[2.6894143e-01 7.3105854e-01]
[9.9987662e-01 1.2339458e-04]], shape=(2, 2), dtype=float32)
형상-Shape 정보
텐서에는 Shape가 있습니다. 위에서 예시를 든 코드에서도 보이듯 말 그대로 텐서가 어떻게 생겼는지를 나타냅니다.
- 형상-Shpae : 텐서에서 각 차원(축)의 길이(요소의 수)
- 순위-Rank : 텐서 축(차원)의 수 ex)스칼라는 0순위, 벡터는 1순위
- 축/차원-Axis 또는 Dimension : 텐서에서 어느 한 특정 차원
- 크기-Size : 텐서의 총 항목 수, 곱 형상 벡터
2순위 텐서는 일반적으로 2d공간을 설명하지 않습니다.
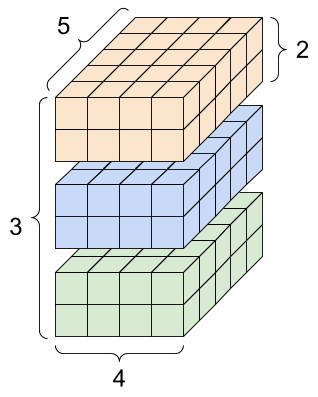
텐서 및 ‘tf.TensorShape’ 객체에 tf.zeros메소드를 이용해 4차원 텐서를 생성 후 속성들을 볼 수 있습니다.
rank_4_tensor = tf.zeros([3, 2, 4, 5])
print("모든 요소의 타입 :", rank_4_tensor.dtype)
print("축(차원)의 수 :", rank_4_tensor.ndim)
print("텐서의 모양 :", rank_4_tensor.shape)
print("텐서의 첫번째 축 요소 수 :", rank_4_tensor.shape[0])
print("텐서의 마지막 축 요소 수 :", rank_4_tensor.shape[-1])
print("모든 요소의 수(3*2*4*5) :", tf.size(rank_4_tensor).numpy())
output
모든 요소의 타입 : <dtype: 'float32'>
축(차원)의 수 : 4
텐서의 모양 : (3, 2, 4, 5)
텐서의 첫번째 축 요소 수 : 3
텐서의 마지막 축 요소 수 : 5
모든 요소의 수(3*2*4*5) : 120
인덱싱
단일 축- 인덱싱
TensorFlow는 표준 파이썬 인덱싱 규칙과 numpy 인덱싱의 기본 규칙을 따릅니다.
- 인덱스는 0부터 시작
- 음수 인덱스는 끝에서부터 거꾸로 계산
- 콜론
:은 슬라이스 ‘start:stop:step’에 사용
rank_1_tensor = tf.constant([0, 1, 1, 2, 3, 5, 8, 13, 21, 34])
print(rank_1_tensor.numpy())
output
[ 0 1 1 2 3 5 8 13 21 34]
스칼라를 사용하여 인덱싱하면 축(차원)이 제거됩니다.
print("첫번째 :", rank_1_tensor[0].numpy())
print("두번째 :", rank_1_tensor[1].numpy())
print("마지막 :", rank_1_tensor[-1].numpy())
output
첫번째 : 0
두번째 : 1
마지막 : 34
:슬라이스를 사용하여 인덱싱하면 축이 유지됩니다.
print("전체 :", rank_1_tensor[:].numpy())
print("4번 인덱스 이전 :", rank_1_tensor[:4].numpy())
print("4번 인덱스부터 끝까지 :", rank_1_tensor[4:].numpy())
print("2번 인덱스부터 7번인덱스 전까지:", rank_1_tensor[2:7].numpy())
print("2개씩 건너뛰어서 인덱싱 :", rank_1_tensor[::2].numpy())
print("거꾸로 :", rank_1_tensor[::-1].numpy())
output
전체 : [ 0 1 1 2 3 5 8 13 21 34]
4번 인덱스 이전 : [0 1 1 2]
4번 인덱스부터 끝까지 : [ 3 5 8 13 21 34]
2번 인덱스부터 7번인덱스 전까지: [1 2 3 5 8]
2개씩 건너뛰어서 인덱싱 : [ 0 1 3 8 21]
거꾸로 : [34 21 13 8 5 3 2 1 1 0]
다축 인덱싱
더 높은 차원의 텐서는 여러 인덱스를 전달하여 인덱싱됩니다.
단일 축-벡터에서와 같은 규칙이 각 축에 독립적으로 적용됩니다.
print(rank_2_tensor.numpy())
output
[[1. 2.]
[3. 4.]
[5. 6.]]
각 인덱스에 정수를 전달하면 스칼라가 결과로 나옵니다.
print(rank_2_tensor[1, 1].numpy())
output
4.0
정수와 슬라이스를 조합하여 인덱싱 할 수 있습니다.
print("두번째 행 :", rank_2_tensor[1, :].numpy())
print("두번째 열 :", rank_2_tensor[:, 1].numpy())
print("마지막 행 :", rank_2_tensor[-1, :].numpy())
print("첫번째 행 제외 :")
print(rank_2_tensor[1:, :].numpy())
output
두번째 행 : [3. 4.]
두번째 열 : [2. 4. 6.]
마지막 행 : [5. 6.]
첫번째 행 제외 :
[[3. 4.]
[5. 6.]]
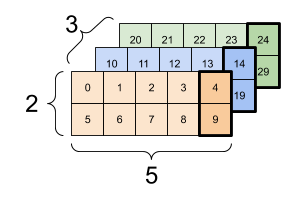
3차원 텐서의 예시입니다.
print(rank_3_tensor.numpy())
output
[[[ 0 1 2 3 4]
[ 5 6 7 8 9]]
[[10 11 12 13 14]
[15 16 17 18 19]]
[[20 21 22 23 24]
[25 26 27 28 29]]]
print(rank_3_tensor[:, :, 4])
output
tf.Tensor(
[[ 4 9]
[14 19]
[24 29]], shape=(3, 2), dtype=int32)
형상-Shape 조작
shape는 각 차원의 크기를 보여주는 TensorShape 객체를 리턴합니다.
var_x = tf.Variable(tf.constant([[1], [2], [3]]))
print(var_x.shape)
output
(3, 1)
해당 객체를 파이썬의 리스트로 변환할 수 있습니다.
print(var_x.shape.as_list())
print(var_x.shape.as_list()[0])
output
[3, 1]
3
텐서를 새로운 shape으로 바꿀 수 있습니다. 리스트를 거치므로 기존 텐서와 새로운 shape의 텐서의 요소 수가 같아야 함에 주의해야합니다.
기존 데이터를 복제할 필요가 없으므로 재구성이 빠르고 저렴합니다.
reshaped = tf.reshape(var_x, [1, 3])
print(var_x.numpy())
print(var_x.shape, "\n")
print(reshaped.numpy())
print(reshaped.shape)
output
[[1]
[2]
[3]]
(3, 1)
[[1 2 3]]
(1, 3)
데이터는 메모리에서 레이아웃을 유지하고, 요청된 형상-shape으로 동일 데이터를 가리키는 새로운 텐서를 생성됩니다. 텐서플로우는 C 스타일의 “행 중심” 메모리 순서를 사용하는데, 여기서 가장 오른쪽 인덱스를 증가시키는 것은 메모리의 단일 단계에 해당합니다.
print(rank_3_tensor.numpy(), "\n")
print(tf.reshape(rank_3_tensor, [-1]).numpy())
텐서를 평평하게 하면 어떤 순서로 메모리에 배치되어있는지 파악하기 편해집니다.
output
[[[ 0 1 2 3 4]
[ 5 6 7 8 9]]
[[10 11 12 13 14]
[15 16 17 18 19]]
[[20 21 22 23 24]
[25 26 27 28 29]]]
[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
24 25 26 27 28 29]
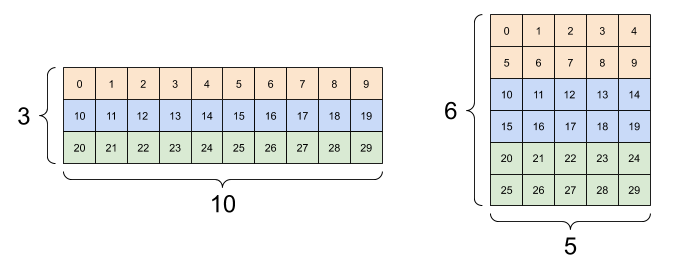
일반적인 tf.reshape의 용도는 인접한 축을 결합하거나 분할합니다.(1을 추가하거나 제거하는 것)
이 3x2x5 텐서의 경우 (3x2)x5 또는 3x(2x5)로 재구성하는 것이 합리적입니다.
print(tf.reshape(rank_3_tensor, [3*2, 5]), "\n")
print(tf.reshape(rank_3_tensor, [3, -1]))
output
tf.Tensor(
[[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]
[15 16 17 18 19]
[20 21 22 23 24]
[25 26 27 28 29]], shape=(6, 5), dtype=int32)
tf.Tensor(
[[ 0 1 2 3 4 5 6 7 8 9]
[10 11 12 13 14 15 16 17 18 19]
[20 21 22 23 24 25 26 27 28 29]], shape=(3, 10), dtype=int32)
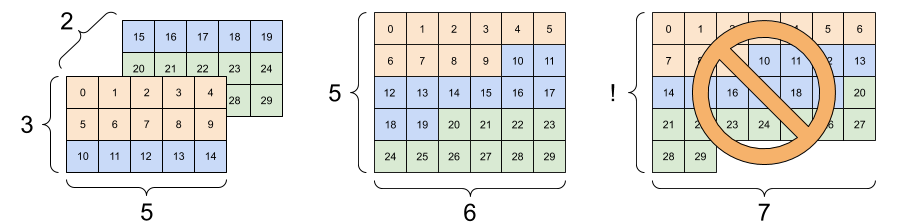
새로운 형상으로 형상 변경 시 총 요소 수가 같으면 rf.reshape이 작동하지만, 축의 순서를 고려하지 않으면 별로 쓸모가 없습니다.
‘tf.reshape’에서 축 교환이 작동되지 않으면 ‘tf.transpose’를 사용해야합니다.
print(tf.reshape(rank_3_tensor, [2, 3, 5]), "\n")
print(tf.reshape(rank_3_tensor, [5, 6]))
output
tf.Tensor(
[[[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]]
[[15 16 17 18 19]
[20 21 22 23 24]
[25 26 27 28 29]]], shape=(2, 3, 5), dtype=int32)
tf.Tensor(
[[ 0 1 2 3 4 5]
[ 6 7 8 9 10 11]
[12 13 14 15 16 17]
[18 19 20 21 22 23]
[24 25 26 27 28 29]], shape=(5, 6), dtype=int32)
형상에 ‘None’(축 길이 알수없음)이 포함되거나 전체 형상이’None’(텐서 순위 알수없음)인 완전히 지정되지 않은 형상 전체에 걸쳐 실행 가능합니다.
‘tf.function’, keras 함수형 API같은 ‘TensorFlow’의 상징적인 그래프 빌딩 API의 컨텍스트에서만 발생합니다. 이때 ‘tf.RaggedTensor’는 제외됩니다.
RaggedTensor는 더 밑에서 설명합니다.
브로드캐스팅
특정 조건에서 작은 텐서가 결합 연산을 실행하면 더 큰 텐서에 맞게 자동으로 확장되는 개념입니다.
가장 간단하고 일반적인 경우는 스칼라에 텐서를 곱하거나 추가하려는 경우입니다. 이 때, 스칼라는 다른 인수와 같은 형상으로 브로드캐스트됩니다.
x = tf.constant([1, 2, 3])
y = tf.constant(2)
z = tf.constant([2, 2, 2])
print(tf.multiply(x, 2))
print(x * y)
print(x * z)
output
tf.Tensor([2 4 6], shape=(3,), dtype=int32)
tf.Tensor([2 4 6], shape=(3,), dtype=int32)
tf.Tensor([2 4 6], shape=(3,), dtype=int32)
크기가 1인 축은 다른 인수와 일치하도록 확장할 수 있으며 두 인수 모두 같은 계산으로 확장할 수 있습니다.
이 경우 3x1 행렬에 요소별로 1x4 행렬을 곱하여 3x4 행렬을 만듭니다. y의 형상은 ‘[4]’입니다.
x = tf.reshape(x,[3,1])
y = tf.range(1, 5)
print(x, "\n")
print(y, "\n")
print(tf.multiply(x, y))
output
tf.Tensor(
[[1]
[2]
[3]], shape=(3, 1), dtype=int32)
tf.Tensor([1 2 3 4], shape=(4,), dtype=int32)
tf.Tensor(
[[ 1 2 3 4]
[ 2 4 6 8]
[ 3 6 9 12]], shape=(3, 4), dtype=int32)
브로드캐스팅 없이 같은 연산은 아래와 같이 시도해야합니다.
x_stretch = tf.constant([[1, 1, 1, 1],
[2, 2, 2, 2],
[3, 3, 3, 3]])
y_stretch = tf.constant([[1, 2, 3, 4],
[1, 2, 3, 4],
[1, 2, 3, 4]])
print(x_stretch * y_stretch)
output
tf.Tensor(
[[ 1 2 3 4]
[ 2 4 6 8]
[ 3 6 9 12]], shape=(3, 4), dtype=int32)
브로드캐스팅은 브로드캐스트 연산으로 메모리에서 확장된 텐서를 구체화하지 않기 때문에 시간과 공간적으로 효율적입니다.
tf.broadcast_to를 사용하여 브로드캐스팅이 어떤 모습인지 알 수 있습니다.
print(tf.broadcast_to(tf.constant([1, 2, 3]), [3, 3]))
output
tf.Tensor(
[[1 2 3]
[1 2 3]
[1 2 3]], shape=(3, 3), dtype=int32)
tf.convert_to_tensor
tf.matmul 및 tf.reshape와 같은 대부분의 연산은 클래스 tf.Tensor의 인수를 사용합니다. 그러나 텐서 형상의 Python 객체가 수용될 수 있습니다.
전부는 아니지만 대부분의 연산은 텐서가 아닌 인수에 대해 convert_to_tensor를 호출합니다.
변환 레지스트리가 있어서 NumPy의 ndarray, TensorShape, Python의 list, tf.Variable과 같은 대부분의 객체 클래스는 자동으로 변환됩니다.
비정형 텐서
어떤 축마다 다양한 수의 요소를 가진 텐서를 비정형(ragged)텐서라고 합니다.
비정형 텐서는 정규 텐서로 표현할 수 없으므로 비정형 데이터에 tf.ragged.RaggedTensor를 사용합니다.
ragged_list = [
[0, 1, 2, 3],
[4, 5],
[6, 7, 8],
[9]]
try:
tensor = tf.constant(ragged_list)
except Exception as e:
print(f"{type(e).__name__}: {e}")
output
ValueError: Can't convert non-rectangular Python sequence to Tensor.
정규 텐서를 썻더니 에러가 났습니다.
다음은 ‘tf.ragged.constant’를 사용합니다.
ragged_tensor = tf.ragged.constant(ragged_list)
print(ragged_tensor)
output
<tf.RaggedTensor [[0, 1, 2, 3], [4, 5], [6, 7, 8], [9]]>
‘tf.RaggedTensor’가 작성되었습니다.
그리고 tf.RaggedTensor의 shape에는 길이를 알 수 없는 축이 포함되어있습니다. 이는 축마다 요소의 수가 다르기 때문입니다.
print(ragged_tensor.shape)
output
(4, None)
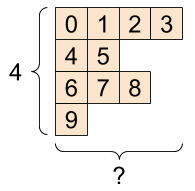
문자열 텐서
tf.string은 텐서에서 문자열(가변 길이 바이트 배열)과 같은 데이터를 나타낼 수 있습니다.
문자열은 원자성, 즉 나눌 수 없으므로 Python 문자열과 같은 방식으로 인덱싱할 수 없습니다.
문자열의 길이는 텐서의 축 중 하나가 아닙니다.
scalar_string_tensor = tf.constant("Gray wolf")
print(scalar_string_tensor)
output
tf.Tensor(b'Gray wolf', shape=(), dtype=string)
tensor_of_strings = tf.constant(["Gray wolf",
"Quick brown fox",
"Lazy dog"])
print(tensor_of_strings)
output
tf.Tensor([b'Gray wolf' b'Quick brown fox' b'Lazy dog'], shape=(3,), dtype=string)
출력에서 b 접두사는 tf.string dtype이 유니코드 문자열이 아니라 바이트 문자열임을 나타냅니다.
유니코드 문자를 전달하면 UTF-8로 인코딩됩니다.
tf.constant("🥳👍")
output
<tf.Tensor: shape=(), dtype=string, numpy=b'\xf0\x9f\xa5\xb3\xf0\x9f\x91\x8d'>
tf.strings을 포함한 문자열의 기본 함수는 tf.strings.split에서 찾을 수 있습니다.
문자열을 텐서 세트로 분리하기 위해 분할-split을 사용할 수 있습니다.
그러나 각 문자열이 다른 수의 요소로 분할될 수 있기 때문에 축의 개수가 1이상인 문자열 텐서를 분리하면 비정형 텐서로 리턴됩니다.
print(tf.strings.split(scalar_string_tensor, sep=" "))
print(tf.strings.split(tensor_of_strings))
output
tf.Tensor([b'Gray' b'wolf'], shape=(2,), dtype=string)
<tf.RaggedTensor [[b'Gray', b'wolf'], [b'Quick', b'brown', b'fox'], [b'Lazy', b'dog']]>

tf.string.to_number 메소드를 이용하면 숫자로 이루어진 문자열 텐서를 숫자로 변환할 수 있습니다.
text = tf.constant("1 10 100")
print(tf.strings.to_number(tf.strings.split(text, " ")))
output
tf.Tensor([ 1. 10. 100.], shape=(3,), dtype=float32)
‘tf.cast’를 사용하여 문자열을 숫자로 변환할 수는 없지만 바이트로 변환 후 숫자로 변환할 수 있습니다.
byte_strings = tf.strings.bytes_split(tf.constant("Duck"))
byte_ints = tf.io.decode_raw(tf.constant("Duck"), tf.uint8)
print("Byte strings:", byte_strings)
print("Bytes:", byte_ints)
output
Byte strings: tf.Tensor([b'D' b'u' b'c' b'k'], shape=(4,), dtype=string)
Bytes: tf.Tensor([ 68 117 99 107], shape=(4,), dtype=uint8)
혹은 유니코드로 해독한 다음 분할하면 됩니다.
unicode_bytes = tf.constant("アヒル 🦆")
unicode_char_bytes = tf.strings.unicode_split(unicode_bytes, "UTF-8")
unicode_values = tf.strings.unicode_decode(unicode_bytes, "UTF-8")
print("Unicode bytes:", unicode_bytes)
print("\nUnicode chars:", unicode_char_bytes)
print("\nUnicode values:", unicode_values)
output
Unicode bytes: tf.Tensor(b'\xe3\x82\xa2\xe3\x83\x92\xe3\x83\xab \xf0\x9f\xa6\x86', shape=(), dtype=string)
Unicode chars: tf.Tensor([b'\xe3\x82\xa2' b'\xe3\x83\x92' b'\xe3\x83\xab' b' ' b'\xf0\x9f\xa6\x86'], shape=(5,), dtype=string)
Unicode values: tf.Tensor([ 12450 12498 12523 32 129414], shape=(5,), dtype=int32)
희소 텐서
텐서에 모양에 비해 데이터가 희소한 경우(축행렬에 비어있는 곳이 존재)가 있습니다.
‘tf.sparse.SparseTensor’를 사용하면 값이 존재하는 인덱스에 따라 해당 값들만 저장하여 희소 데이터를 효율적으로 저장합니다.
sparse_tensor = tf.sparse.SparseTensor(indices=[[0, 0], [1, 2]], #값이 존재하는 곳의 인덱스
values=[1, 2], #인덱스에 해당하는 값
dense_shape=[3, 4]) #실제 희소 텐서의 모양
print(sparse_tensor, "\n")
#희소 텐서를 dense로 바꿀 수 있습니다.
print(tf.sparse.to_dense(sparse_tensor))
output
SparseTensor(indices=tf.Tensor( [[0 0] [1 2]], shape=(2, 2), dtype=int64), values=tf.Tensor([1 2], shape=(2,), dtype=int32), dense_shape=tf.Tensor([3 4], shape=(2,), dtype=int64))
tf.Tensor( [[1 0 0 0] [0 0 2 0] [0 0 0 0]], shape=(3, 4), dtype=int32)
